
Whether you think about them or not, data structures are an important part of all of our lives. They are found in both the man-made world and in nature. While uniquely beautiful and interesting when found in nature, data structures are absolutely critical in computer science and algorithm design. Having a strong command of data structures will put you in a great position to succeed in your use case.
Linked Lists
The linked list data structure is one of the more interesting data structures found in computer science. While it has its own limitations, the linked list is very useful when you need a sequentially organized group of items and efficient insertion and deletion. A linked list is comprised of nodes that are “chained” together. Each node contains a piece of data and a pointer to the next node in the sequence. There are other variations of the linked list that have pointers to multiple other nodes, but we’ll focus on the singly linked list.

If you’re looking for a real-world example of a linked list, you may find it a bit difficult to find anything obvious and immediate. Linked lists are a bit of a man-made abstraction, but the best analogy I could think of is that linked lists are like neurons.
In the human body, neurons are interconnected throughout the body and send signals to and from your brain. They often chain together sequentially in a “neural circuit” to relay nerve impulses over longer distances of the body. This chaining to send signals from one neuron to the next is analogous to how a linked list works.
Efficiency
Efficiency is always an important consideration when dealing with data structures and linked lists are no exception. Whether you’re designing an algorithm for an interview or an application, you’ll need to choose the right data structure to use for your situation.
The efficiency of data structures is typically defined in terms of time and space complexity, and it’s often described using Big O notation. To get an idea of the different data structures and their efficiencies, check out this popular cheatsheet.
Generally, if we’re just evaluating data structures in isolation and not evaluating an entire algorithm, we’re only really interested in the time complexity because the space complexity is often trivially going to be linear (i.e. O(n)). We’re also typically just comparing worst-case scenarios when evaluating data structures because for small amounts of data the differences in efficiency become negligible.
When used properly, linked lists are great for insertions and deletions. This is because unlike with arrays where we have to reposition all of the items that occur after the insertion or deletion, linked lists use pointers so we only have to repoint the relevant nodes to their new targets. Due to this innovative design, linked lists have a “constant” time complexity (i.e. O(1)) for insertions and deletions. However, if you need to look up an item other than the “head” of the list, you’re going to need to iterate through each node of the linked list until you find it. This is because linked lists are designed for sequential access instead of random access.
Knowing the efficiencies of each data structure is very helpful in algorithm design, but knowing how each data structure is implemented will help you to be able to derive these efficiencies on the spot. Next, we’ll take a look at a JavaScript implementation.
Implementation in JavaScript
To implement a linked list, you’ll need to implement a node. As described previously, a node just holds a value and points to the next node. Let’s take a look at the implementation below.
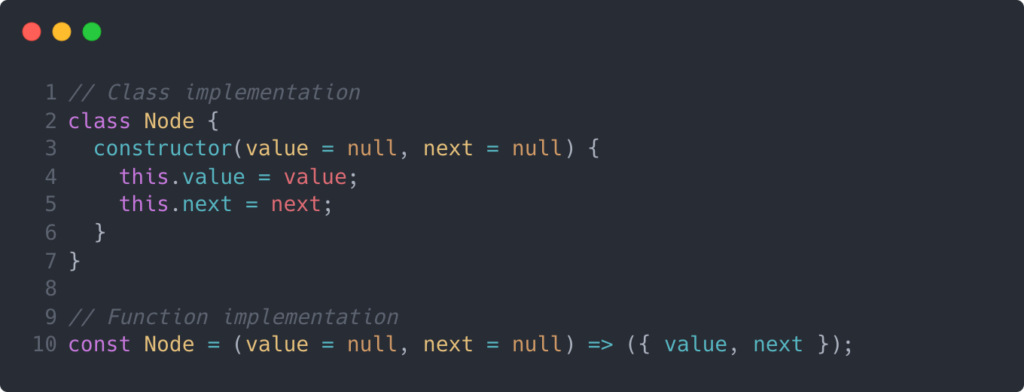
For clarity, I’ve shown a class implementation and a function implementation. Effectively both designs perform the same, but you may have a preference for object-oriented programming, or maybe you like that the function implementation might minify better in certain cases.
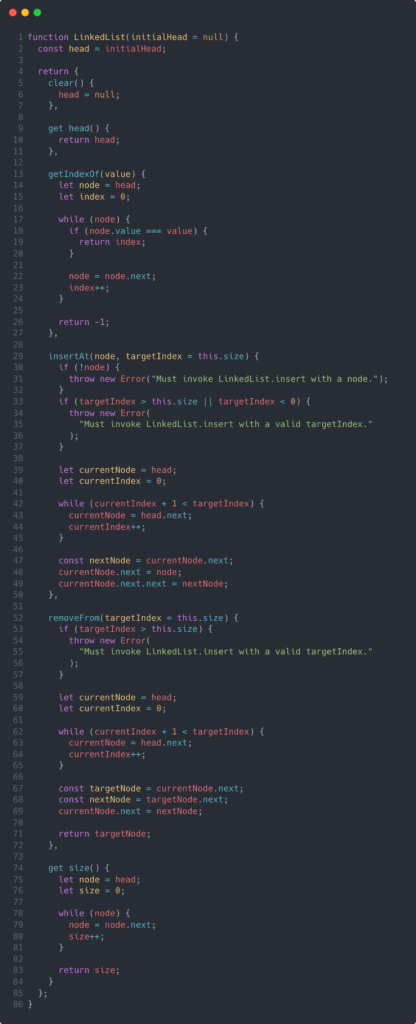
Now, let’s take a look at the linked list. At the very minimum, you really don’t need to implement a LinkedList class. All you technically need is the Node class because you can just point each node where it needs to point, and you can manually insert, delete, count, and whatever else you might need. However, it’s not practical to implement insert logic every time you need to insert a node into a linked list anywhere in your application. So let’s take a look at some common methods and their implementations below.

I’ll go through each method one by one:
- clear
While not that useful, a clear method can be implemented for convenience. We simply reassign ourheadto null. - getIndexOf
This method can be helpful when you need to check for the existence of a value in the linked list. The implementation is fairly simple. We iterate through the list while keeping track of the currentindex. When we find the value, we simply return theindex. Otherwise, we’ll return-1, which is a common convention. - insertAt
This is a commonly used method because inserting into a linked list is critical. I’ve designed my implementation to accept two parameters: anodeand atargetIndex. As you can see on lines27through34, I’ve implemented a couple of safeguards so that you aren’t trying to insert a node inappropriately. From there, we just iterate through the nodes until we get to the node that is precisely one node before our target index. We do this because we need to store a reference to that node so that we can reassign itsnextpointer to the node we’re inserting. We do this reassignment on line45. Then on line46, we direct our inserted node’snextpointer to be pointing to the remaining nodes in the list. - removeFrom
This method is completely analogous toinsertAt. Instead of inserting a node at an index, we’re removing a node at that index. Thus, we only accept one parameter to this method, thetargetIndex. We similarly iterate through the list until we get to the node before thetargetIndex. We then just point that node to the node after the node at ourtargetIndex. We don’t need to delete that node because it will be cleaned up in garbage collection. Finally, we return that removed node just in case the consumer needs it. - size
This method simply returns the number of nodes in the list. To do this, we just iterate through the list and count all of the nodes along the way.
When working with data structures and algorithms, it’s critically important to make sure your mental model is rock solid. So just to help you solidify your mental model, I’ve illustrated the insertion routine below:

I know that was a lot, but when you break down each method, it really just comes down to iterating through the list and storing a reference to what you need. And just for your convenience, I’ve created a function implementation of the linked list with the same methods. Take a look:
Conclusion
The linked list is a cleverly designed data structure that is optimized for insertions and deletions. They are commonly used to help create more complicated data structures and show up frequently in algorithm design interview questions for software engineer jobs. Hopefully, this article has helped you, and if it has, be sure to let me know your thoughts in the comments, and also follow for more similar content. Thanks!
Michael has a diverse background in software engineering, mechanical engineering, economics, and management. After a successful career in mechanical engineering, Michael decided to become a software engineer and attended the Hack Reactor coding bootcamp. Michael enjoys writing about his experiences and helping others start their journies in software development.
One response
[…] about how to build other fundamental data structures in JavaScript, check out this article How to Build a Linked List in JavaScript. Or if you’re thinking about joining a coding bootcamp, 10 Things I Learned as a Coding […]