
Data structures are an integral part of your life, whether you notice them or not. From waiting in line at the grocery store to something more obvious like the glossary in a textbook, they’re everywhere. However, they are especially important in software engineering and the algorithm interview questions that are asked during technical interviews.
Stacks
A stack is an important type of data structure used in engineering and computer science, and it has certain properties that make it especially useful. Stacks can be described as a Last In First Out (LIFO) data structure. This means that each time you want to remove an item, the stack will provide you with the most recently added item. Imagine you work at a restaurant in the kitchen and you need to plate an order. You have a tall stockpile of dinner plates in front of you. Now imagine you grab a plate from the plate pile. What part of the pile did you reach for? Logically you would reach for one from the top and begin arranging the meal on it. While you could have lifted half of the plates, took a plate from the middle, and set the remaining plates back on top of the pile, this would have been a lot more work.

Other good examples of stacks in real life are browser histories, clothing (it would be rather difficult to remove your shirt before you take off your jacket), or anything that is stored vertically like maybe some dining chairs.
Efficiency
Now that we generally understand how stacks work and where they’re used in real life, let’s talk about their efficiency. Data structure efficiency is often measured using Big O notation for both time complexity and space complexity, but we’re generally only concerned with time complexity when simply evaluating data structures. We’re also often only interested in the worst-case scenarios (i.e. when there is a lot of data) because differences in time complexity efficiency for small amounts of data are often trivial or unreliable.
Stacks are well-suited for insertion and deletion because they keep an active reference pointing at the most recent item added. Because of this, their time complexity for insertion and deletion are considered constant time (i.e. O(1)). However, if you need to be able to look up any other item other than the latest item added to the stack, you may want to use a different data structure that is better optimized for that scenario. While you might consider stacks to have linear lookup time complexity (i.e. O(n)), you would need to remove all of the items that were added after your target item in order to read it.
With all of that said, stacks are very efficient when used properly. If you want to see a comparison of common data structures and their efficiencies, you can take a look at this popular cheatsheet.
Implementation in JavaScript
Generally speaking, a stack needs to be able to push and pop the latest item, as well as allow users to read its length. Below is a class implementation of a basic stack in JavaScript.
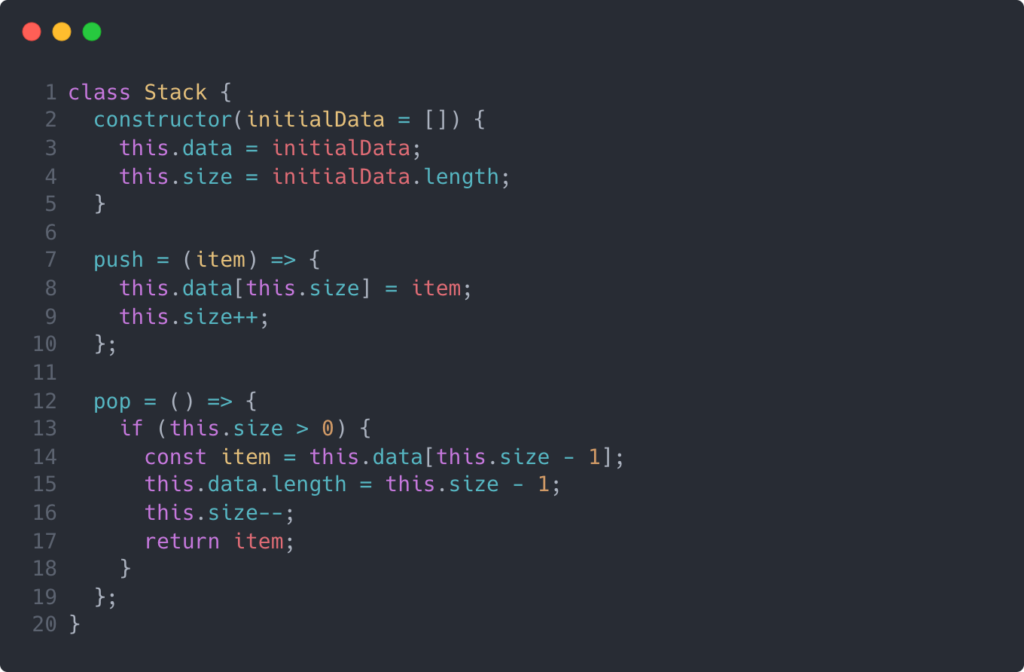
Let’s talk about how this works. Here on lines 2 through 5, we initialize our stack class with data and size properties attached to the instance. If the stack is instantiated without any initial data, the data property will be assigned an empty array and the size property will be 0.
You may have noticed that I used arrow function expressions for the instance methods defined on lines 7 and 12. Because arrow function expressions don’t have their own this bindings, the references to this in the function definitions will evaluate to the this found in the scope where the functions were defined. This is a minor convenience here, but I thought it would be worth explaining.
I also want to draw your attention statement on line 15. This shortens the length of the data array and effectively deletes any items that reside at indices beyond that length. Theoretically, this implementation can vary depending on the JavaScript engine being used, and for the sake of this post, I’ve assumed this is a constant time operation. However, since we’re tracking our own size property, we don’t even need to shrink the array when we pop an item off. We could just delete the item in the array and decrement our size variable.
One thing you might also have noticed is that our data and size properties are assigned onto the instance, and this could be considered “leaky.” Some developer could directly mutate the data or size properties and potentially break the stack functionality. Let’s see how we might get around this with a functional implementation.
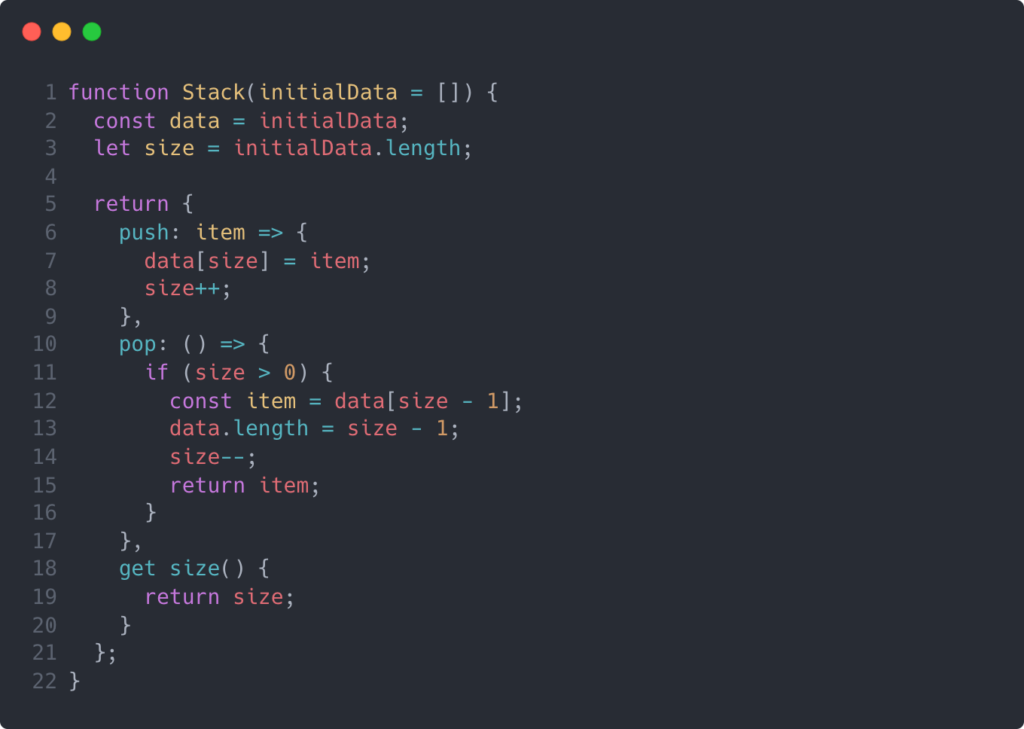
In this implementation, I make use of a JavaScript closure to encapsulate our data and size values. In JavaScript, when a function is declared, it is given access to the lexical environment in which it was created. So by creating local variables within our Stack function and returning an object with methods that reference those variables, we’re in full control of how we allow access and manipulation of those variables. This will help reduce bugs associated with leaky variables, and it’s just as readable and scannable as our class-based solution.
Conclusion
Stacks are very useful data structures in software engineering and in the everyday world. They are particularly efficient for data insertion and deletion when used correctly. Hopefully, you’ve learned a thing or two about how to implement them in JavaScript, but let me know in the comments if you have any questions!
Michael has a diverse background in software engineering, mechanical engineering, economics, and management. After a successful career in mechanical engineering, Michael decided to become a software engineer and attended the Hack Reactor coding bootcamp. Michael enjoys writing about his experiences and helping others start their journies in software development.