
What is Memoization?
In software programming, memoization is a technique used to make applications run faster. If you have a function with high time complexity that blocks execution for too long, or your application has a function that is invoked frequently such that a small optimization in time complexity results in a much faster overall runtime, memoization can shorten execution times and improve user experiences.
Outside of software engineering, there are many examples in the real world that are analogous to memoization. Frequently Asked Question (FAQ) pages are a perfect example of where certain questions are asked so often that sites will dedicate resources to preemptively provide those answers to their users so they don’t have to search for them.
How Memoization Optimization Works
In software, optimization often comes in two forms: reducing superfluous complexity or substituting one complexity for another. Memoization optimizes for runtime by utilizing more memory. Therefore, memoization often decreases the time complexity of an algorithm by increasing the space complexity.
Under the hood, the logic is actually quite simple. For any memoized function, we first check if that function has been invoked with the current parameters. If it hasn’t, we compute the resultant value, store the input/output pair in a cache, and return the value from the function. On the other hand, if the function has already been invoked with the given parameters, the resultant value will already be cached. So in this case, the function will simply return the cached value without recomputing.
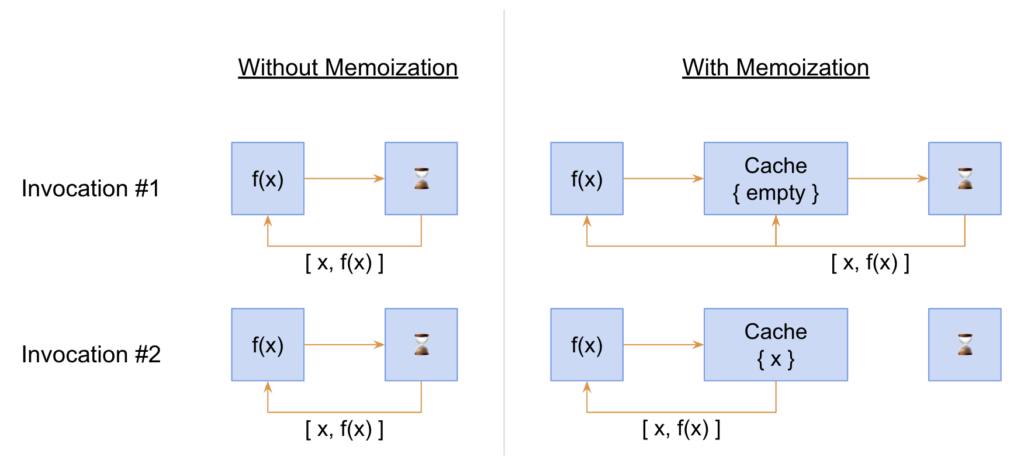
In the illustration above, the left side shows how the basic flow logic of a function invocation while the right side illustrates memoization. Without memoization, the flow logic for each function invocation is identical: invoke, compute, then return. In contrast, with memoization, there is an intermediate step involving the cache. If the function has yet to be invoked with the parameter permutation, the flow logic is: invoke, check cache, compute, cache result, then return. However, if the function has already encountered these parameters previously, the flow simplifies to: invoke, check cache, then return. Notice that the expensive “compute” step is bypassed on the second invocation. That is the crux of memoization; if the function is computationally expensive, memoization will bypass that step on subsequent invocations.
The logic behind memoization is actually quite simple itself, but it builds upon a few important concepts that are fundamental.
Deterministic Functions
In mathematics and computer science, a function is considered deterministic if the function repeatably produces the same result for a given set of parameters. If a function is not deterministic, memoization can’t be used because the cached value would only reflect the first invocation for a given parameter set. A nondeterministic function is one that depends on something that changes to produce its resultant value.
function deterministicFunc(x) {
return x + 2;
}
function nonDeterministicFunc(x) {
return x + Date.now();
}Examples of a deterministic function and a non-deterministic function
In the example above, the deterministicFunc function will always produce the same result for the same given parameter (and the same runtime environment). For example, when deterministicFunc is passed x = 2, it will always return 4. However, the nonDeterministicFunc function doesn’t work the same way. Because the Date.now invocation will return the current timestamp in milliseconds, this function will return a new value each time. Go ahead and try it out; if you’re in a Chrome browser, hit command + option + j to open the dev tools (control + shift + j on a PC), paste in the functions, and invoke them with a parameter.
Function Closures
Function closures are a fundamental pillar of computer science and a powerful feature of JavaScript where an inner function retains access to variables from its outer (enclosing) function, even after that outer function has finished executing. This works because JavaScript functions create their own scope, and closures let inner functions access variables from their parent scope. Closures are crucial for data encapsulation, maintaining state, and creating more sophisticated constructs like memoization.
When a function is returned from another function, it “closes over” the variables in its scope, preserving their values. This behavior enables developers to maintain private variables and state within functions, which is useful for tasks such as caching results or handling asynchronous operations.
function outerFunction() {
let counter = 0; // This variable is part of the closure
return function innerFunction() {
counter++;
console.log(`Counter value: ${counter}`);
};
}
const incrementCounter = outerFunction(); // Create a closure
incrementCounter(); // Output: Counter value: 1
incrementCounter(); // Output: Counter value: 2
An example of a function closure in JavaScript
In this example, the outerFunction defines a local variable counter, the innerFunction is returned and maintains access to the counter variable through a closure, and even though outerFunction has finished executing, the counter variable remains accessible whenever incrementCounter is called. Closures are particularly useful for memoization because they allow functions to “remember” previous inputs and outputs, enabling efficient caching.
Higher Order Functions
Higher order functions are those that take one or more functions as arguments, return another function, or do both. This concept is a cornerstone of functional programming, enabling flexible, reusable, and composable code. Higher-order functions treat functions as first-class citizens, meaning functions can be stored in variables, passed as arguments, and returned from other functions.
Higher-order functions and closures are foundational to implementing memoization in JavaScript. They enable memoization by wrapping a function with caching logic without changing its core behavior. A memoization function takes another function as input, adds caching, and returns an optimized version for reuse across multiple scenarios.
function applyOperation(array, operation) {
// Applies the passed function to each element
return array.map(operation);
}
// Example usage
const numbers = [1, 2, 3, 4];
const square = (x) => x * x;
const squaredNumbers = applyOperation(numbers, square);
console.log(squaredNumbers); // Output: [1, 4, 9, 16]An example of a higher order function in JavaScript
Here, the applyOperation function is a higher-order function because it takes another function (operation) as an argument. The operation function is applied to each element of the array using the map method. By passing a specific operation like square, we can easily customize the behavior of applyOperation without changing its implementation.
Memoization Implementation in JavaScript
In software development, we usually try to avoid reinventing the wheel. However, in software interviews, we’re often tasked with doing exactly that. Let’s reinforce our understanding of memoization through JavaScript examples.
A Basic Implementation of a Memoization Function
At its core, a memoization function needs to track if a function has been invoked with the same given parameters previously and return that cached value if it has. Let’s create a function in JavaScript that does exactly that.
function memoize(fn) {
const cache = new Map();
return function (...args) {
const key = JSON.stringify(args);
if (cache.has(key)) {
return cache.get(key);
} else {
const result = fn(...args);
cache.set(key, result);
return result;
}
};
}There are four main aspects of this function that warrant discussion:
- Cache Storage: The
Mapobject is used to store cached results, with keys derived from the function arguments. - Key Generation: The arguments are converted to a unique string key using
JSON.stringify. - Cache Check: If the key exists in the cache, the function retrieves and returns the cached result.
- New Computations: If the key isn’t found in the
Maplookup, the result is computed, cached, and returned.
This approach makes the function reusable and efficient, especially for computationally expensive tasks with repeated inputs.
An Advanced Implementation of a Memoization Function
The simple implementation works great if our function only accepts simple parameters, like primitives. If we want our memoization function to work with more complex parameters like objects, we’ll need to adjust how we handle these parameters.
However, attempting to memoize functions that accept complex data structures as parameters is more complicated than it may seem initially. This is because data structures are usually mutable — they are often used to dynamically store data — and if the output of your memoized function depends on those data structure properties, you’ll need to serialize all of those to see if they’ve changed between invocations.
So, while memoization is not reliable for data structures that are storing data dynamically, there are scenarios where memoization makes sense for object parameters. Examples of this are when you know your object won’t be mutated, or if an object is immutable like when using Object.freeze() for static data. Let’s take a look at the implementation of the enhanced memoization function to handle object types.
function memoize(fn) {
const cache = new Map();
return function (...args) {
let currentCache = cache;
for (const arg of args) {
const key = typeof arg === 'object' && arg !== null
? arg
: JSON.stringify(arg);
if (!currentCache.has(key)) {
currentCache.set(key, new Map());
}
currentCache = currentCache.get(key);
}
if (currentCache.has('result')) {
return currentCache.get('result');
} else {
const result = fn(...args);
currentCache.set('result', result);
return result;
}
};
}The key improvements of this enhanced version are:
- Nested
MapStructure: Arguments are stored hierarchically in nestedMapobjects, avoiding reliance on stringifying objects. - Object Keys: Objects are directly used as keys when possible, leveraging JavaScript’s ability to store object references in
Map. - Improved Cache Robustness: Handles complex arguments and avoids issues with
JSON.stringify.
Conclusion
Memoization is a powerful programming technique that optimizes function performance by caching the results of expensive computations and reusing them when the same inputs occur. This approach significantly improves efficiency, especially for functions with repetitive and deterministic calculations, by reducing redundant processing.
Memoization is most effective for computationally expensive operations with repeated inputs, such as recursive algorithms or data-heavy tasks. However, it may not be suitable for functions with highly dynamic inputs or when memory usage is a concern, as caching can increase memory consumption.
When working with data structures like Map, Set, or objects as parameters, memoization faces limitations. Cache consistency depends on whether inputs are handled by reference or through serialization. Using references limits reuse to identical instances, while serialization can be computationally expensive and may not handle complex cases like circular references. Understanding these trade-offs helps determine when memoization is the right tool for the job.
Michael has a diverse background in software engineering, mechanical engineering, economics, and management. After a successful career in mechanical engineering, Michael decided to become a software engineer and attended the Hack Reactor coding bootcamp. Michael enjoys writing about his experiences and helping others start their journies in software development.